This post is included in the iKennd.ac Audioblog! Want to listen to this blog post? Subscribe to the audioblog in your favourite podcast app!
Prologue
This post is less of a “blog post” and more of… I dunno, a chapter of a memoir (were I important enough to have such a thing). It was originally written over several weeks in the latter months of 2022 as a way to unjumble the last few years of my life and to have it down somewhere, at least — one of the largest regrets I have of my Dad passing (other than the fact that he, er, died in the first place) was that he died before I was old enough for him to share the stories of his life with me. Every time I hear a snippet about my Dad from someone who knew him before I was born — “After he fled Cuba during the Revolution, he–” Excuse me?! — it’s kinda wild. So, boring as my life is so far compared to parts of his, I have a desire to document it so future people who care about me won’t have the same sorrow.
This was going to stay in scruffily-scrawled fountain pen ink shoved into a drawer until some poor soul has the task of clearing out all of my crap when I’m gone, but slowly the idea of putting it up here has become less awful over time. Nobody likes to share their low points (much less this widely), but people I respect tell me there’s strength in failure, and I’d like to draw a nice, clean line under this whole affair so I can focus on the next thing.
So, below you’ll find 5,000 words or so — or, on the audioblog, 36 minutes or so — about the past four years of my life as an indie developer a small business owner. Enjoy!
If we take a look at my career so far, we can see two things. First — somehow — I’ve been a professional developer for over seventeen years now, which is kind of incredible. The second is that out of those seventeen years, only four and a half of them were actually at a “regular” job.
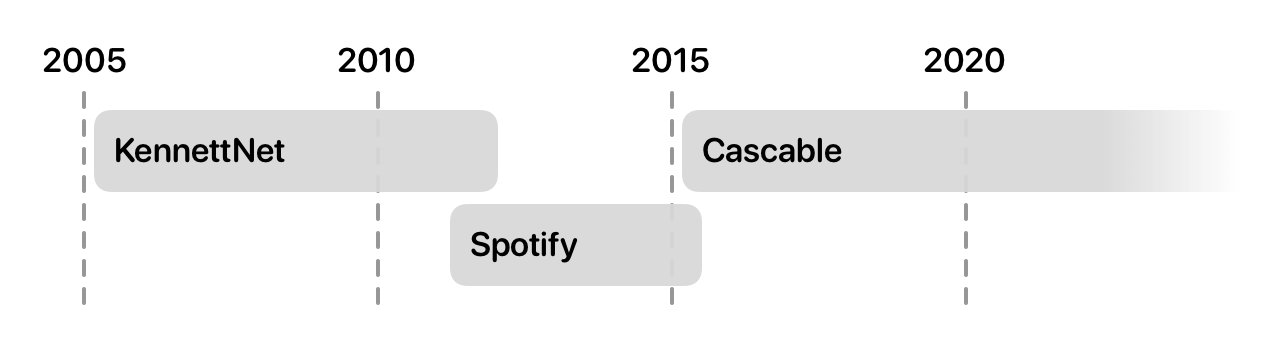
For the rest of the time, I’ve made my way through life identifying as an “indie developer”, despite the fact that neither KennettNet (my first company, 2005–2012) or Cascable (my second company, 2015–) were ever really one-man enterprises. However, they were small companies for which the bulk of the development work was done by me (although even that isn’t true for some significant time periods). Still, in the early days of KennettNet, I struck lucky and wrote an app that sold well with very little non-development (read: marketing) work. I wrote the app, signed up for a payment provider, listed it on VersionTracker and away I went — truly an “indie developer”.

It’s not official until you have a sign.
2011–2015
When KennettNet failed — a long story for another day — I got a job at Spotify and, for the most part, enjoyed my time there. I worked on fun challenges and shipped things I was (and still am) proud of, but grew increasingly frustrated that my career progression there seemed to be circling into a funnel towards management. I firmly hold the belief a good developer should be able to progress through their career entirely doing development work if they want to — effectively becoming an artisan of their craft, as dated as that may sound. At Spotify, I never wanted to play the game of checking the progression boxes they wanted everyone to check to progress through the system. “I’m a developer — just let me be good at my job!”, I’d bluster. Thanks to being afforded the chance to work on some impactful projects I did manage to make salary and career progress based off the back of my work, but it was always a struggle without my nicely-checked boxes.
As a “car guy”, one of the more fantastical weekends of my time at Spotify was being flown out to San Francisco with a friend-slash-colleague for a hackathon at TechCrunch Disrupt. Over a very blurry twenty-four hours, we mashed together the Spotify app with Ford’s then-fledgling Sync AppLink platform to create a tech demo of Spotify in a car. I’d somehow managed to completely miss that TechCrunch Disrupt was somewhat of a Big Deal™, so I sauntered onto the stage and somehow managed to give a successful live tech demo with speech recognition before we headed to the airport and slept the entire flight home.
|
Side anecdote: The plan was for my friend and I to give the demo together, but he ended up not doing it due (if I recall correctly) to nerves and/or tiredness. Since I had no idea of Disrupt's significance, I was just "Sure whatever it's just a tech demo, who cares" and did it on my own. My friend was rather upset that I forgot to mention his name on stage — I promise it wasn't on purpose, I was very tired and had no idea of the significance of that particular stage. |
Back at Spotify, folks were pleased with the demo and I wanted to build car integrations more and more. Of course Spotify should be in every car! I pestered the people I could pester, and always got the same answers anyone working in a large corporation has heard a thousand times — lots of empty words surrounding the core underlying ones of “budget” and “priorities”.
Almost as soon as I’d fixed the financial shitstorm that the failure of KennettNet caused, I started getting the “indie itch” again and started to plan an unpaid sabbatical to give it a bash. After yet another rebuttal on doing car integrations, I signed the paperwork — I was going to be indie again!
The next day, a higher-up who had once been my direct manager ran over to my desk.
“What’s this I hear about your leave? I thought you wanted to do car stuff?”
I explained that I’d heard the word “priorities” one too many times.
“Sign this.” An Apple NDA.
A few months later, Apple announced that Spotify would be one of the first third-party apps to have CarPlay integration, and we shipped it later that year. In the meantime, a car integrations team had been started at Spotify (which for a little while was literally just me and a product owner). I worked on lots of interesting things, and got to travel to and work directly with engineers from a number of car manufacturers. It was an absolute blast.
Unfortunately, my unwillingness to play the career progress game came back to bite me eventually. I put my heart and soul into the projects I worked on, working really hard to make them be the best I could. That worked for a while — being the “passionate engineer” meant that my ability to produce results and largely be left to “get on with it” counterbalanced things like my less than professional reaction to learning a project had been canned the Monday after I lost an entire weekend to making sure it’d pass certification on time — but in the end I wasn’t going anywhere without that “Give three or more presentations at employer branding events” checkmark on my progression sheet.
All this time, the “indie itch” never went away. As I saw much greener engineers get promoted ahead of me because they were better at playing the game, it became strong enough that I dug out my abandoned sabbatical paperwork, resubmitted it, and tried again. Finally, I was free to be an indie developer again. To develop. No more bureaucracy getting in the way of being a great developer. Hell. Yes.

Leaving Spotify with a box of crap from my desk.
2019
The first version of the Cascable app was released in 2015, and had been trundling along as I developed features and experimented with business models in an effort to increase revenue — which slowly but surely climbed as time went on. Every major update I vowed to allocate more time to marketing tasks, and every major update it got pushed aside for more development work and polish. It wasn’t perfect, but the app’s sales combined with some part-time client work here and there made ends meet nicely.
This continued until early 2019, when SanDisk approached the company to add support for one of their hardware accessories to the app. I was thrilled to be approached by such a well-known brand (and the marketing opportunities that’d bring), but adding the support would mean a big rebuild of the app’s photo management features. It needed doing anyway, though, and this rebuild ended up being the tentpole of the next big update — Cascable 4.0!
I was convinced this would be the big one. The new photo management feature was leagues ahead of the old one, and things were turning out great. Unfortunately, rendering grids of images turned out to be a lot more complex than I’d expected — and then, I got the golden email. I was going to WWDC 2019! What a perfect deadline.
After some discussion with my wife, I went all in… and it was brutal. Twelve-hour days, seven days per week through March, April, and May. But at least it’d be temporary. My wife took over all of my household tasks and I brought my work computer home to cut out the commute — I’d roll out of bed, sit at the computer for twelve hours, then roll back into bed to sleep. But at least it’d be temporary. Personal care and grooming went to hell (although hygiene thankfully survived — I was scruffy but clean), as did the perception of time.

My “regular” profile picture against one taken in May 2020. It’s remarkable what good lighting and a smile can hide — but the clues are certainly there.
It nearly killed me, but I shipped it. Thank Christ it was temporary! I was so proud of the release — it was some of my best work to date, and with a SanDisk partnership to boot. I shipped the app, then flew off to San Jose for WWDC for a wonderful time. Being an indie developer is great!
Unfortunately, the worst possible thing happened — absolutely nothing. Nobody gave a shit. Apart from some press coverage focused on the SanDisk integration, Cascable 4.0 had the worst launch in the history of the app. Nobody cared, and sales didn’t budge. My best development work to date — in my whole career — and nobody cared.
This would do bad things to someone in a good state of mind, but after months of soul-crushing and unhealthy levels of work fuelled by the promise of an uplift? It was nearly a death blow. Burnout hit hard, and I could barely even bring myself to think about the app, let alone work on it. I did what I always do in times of trauma — I withdrew into myself. Everywhere you look — my blog, my social media, the release notes of the app — you’ll see a sharp falloff from mid-2019 or so.
Spring 2020
I started to recover from the burnout in early 2020, with client work supporting the business as I regrouped and started to think about the future again. Although the 4.0 release had been catastrophic, I was fortunate that the status quo remained — app sales alone didn’t support the company, but they were healthy enough (and not decreasing) that part-time client work continued to fill the shortfall. Despite the setback, the roof over my head wasn’t in danger and the company had client work and an internal roadmap in place that’d take me well into the summer.
The COVID-19 pandemic delivered the one-two punch of the bottom falling out of the event photography industry (and thus app sales), and the bottom falling out of our major client’s industry (and thus client income). My recovery collapsed, and I was pretty certain that my indie career was absolutely done for. Again. At least I’d have a pandemic to blame for it this time.
Out of sheer desperation, I managed to pull a completely new app out of nowhere and get it to market — and, crucially, revenue — in no time flat. That app was Cascable Pro Webcam, an app that lets you use a ‘real’ camera as a webcam. Its existence is very much in response to the slew of people working from home for the first time, and the increased demand for (and subsequent shortage of) webcams. I was worried that it was a cash grab at first, but the app turned out great — it was fun to write a Mac app again — and sold well. Let’s call it a “rapid reaction to a turbulent market”, then. At any rate, it (and a COVID relief grant from the government) absolutely saved the company from folding. It even got covered by TechCrunch!
Able to breathe once more, it was clear that part of me hadn’t made it through the panic unscathed. I just couldn’t do it any more — something had to change, and my health was plummeting. The most troubling thing of all, though, was that I couldn’t quite put my finger on what I couldn’t do any more or exactly what it was that needed changing. Cascable had being going on for five years at this point, and other than a brief moment in 2018 where it got far too close to the end of its runway, the combination of app sales and client work had always kept it healthy. Even the panic that produced Pro Webcam showed that I could fight and adapt if needed. With the additional revenue stream of that app, the company was even more resilient. So what’s the problem?
Summer 2020
This ate at me until one day in late summer, I found myself packing a month’s work of clothing, technology, and HomePods into a car some complain isn’t suitable for a long weekend, saying goodbye to an outwardly supportive wife with unmistakeable fear in her eyes, and heading deep into the mountains of southern France. I tend to — especially when it comes to extreme decision-making — be better at solving problems from the outside, and you can’t get much more ‘outside’ than a three-day drive to a month-long AirBnB rental promising no concerns other than keeping the pain au chocolat consumption under control. With the day-to-day running of the company out of my mind, the hope was to be free enough to figure out what the problem was, and what I could do to fix it.

When luggage space is at a premium, the HomePod still makes the cut.
As days of European motorways slid past the window, trepidation blossomed into terror. What if the only way to save my health — mental or otherwise — was to shut down Cascable and move on to something else? Could I ever recover from burnout so severe that I’m fleeing to the opposite end of the continent to try to even understand it? Another episode of the Scrubs podcast would drown that out, at least for the time being.
As motorways gave way to mountain passes, my soul started to calm a little.
Guillestre is one of my favourite places in the world. It’s a small village nestled in a valley in the Alps, surrounded by peaks on all sides — although there’s nothing particularly special about it. There’s not much to do, and there are more spectacular views to be found. However, I know it well enough to get around and know some of its nooks and crannies, and the sleepy village pace of life forces you to slow down. It’s very calming.

“Nothing particularly special”.
Once settled in, I started a daily-ish journal to try and get my head in order, first trying to reconcile reality with my state of mind. It wasn’t lost on me that I’d jumped into my two-seater sports car and pissed off to the south of France for a month to try and “figure things out” — I privilege I’m very lucky to be afforded. This, of course, just made me feel worse. My days would swing wildly — I’d be joyful and proud of my achievements one day, then come crashing down the next, admonishing myself for my poor mental and physical health. “It’s a wonder you still have a wife that can bear to look at you,” a particularly low point reads.
As this all started to unravel, my hopes were fading that I could ever reach a solution that didn’t involve shutting down the company. This was more than just burnout — my mental and physical health were so bad that it was clear that Cascable was actively harmful to me. But why?
Eventually, I did arrive at some sort of breakthrough. My entire life, I’ve identified myself as a developer, as a coder. And, trite as it sounds, I care deeply about the pieces of code that I write — it is, after all, the sum of my life and experience as a developer up to the point it’s written. This is workable enough in a larger workplace — other people get to handle the direction of the company and which products to make, and the developers get to put their energy into their craft. Of course on a larger scale development time is just another investment, and those same “other people” can just as easily change course and cancel your projects. However, in a larger company you can grumble at management and move on to the next thing you’re handed. Having a deep, emotional connection to an entire business and its day-to-day details is, well, not a good thing.
The deeper realisation was that the dual-income approach had an implicit tension that was hard to resolve. If neither app sales or client work completely supported the business, everything would have undue pressure put onto it — onto me as the person that had to fix both. “This update must increase revenue.” “I must find a client soon.” I can’t work on one thing without worrying about the other, and that’s not sustainable — and I’m constantly annoyed that client work is taking time out of working on updates that could earn more money and reduce the need for client work in the first place.
Additionally — and getting right down to the core of my identity — is that I considered having to take client work as a failure. My goal is to be an “indie developer”, and selling programming hours to someone else, to me, is a failure of that goal. When I’d grumbled about this in the past, my ever-supportive wife had pointed out that to be able to work 50% on my own projects and 50% for someone else is an incredible achievement that many would love to be able to do. She’s right, of course. Hell, when people ask me how to “go indie”, my answer is to find part-time work to fund the endeavour — unless you have a year or two of salary sitting in the bank, what else can you do? Furthermore, I know multiple people running their own businesses — programming and not — that use consulting hours as an additional income stream to support the business. It’s an intelligent and pragmatic way to run a small company, and I don’t look down on anyone that runs things this way.
And yet. Despite all of this rationality… it nags me. It pulls me down. It grips its tendrils into my being with a single, debilitating word: “failure”.
After weeks of solitude and introspection, I was finally starting to understand… but still had nothing in the form of solutions.
More tendrils. “Failure”.
Thankfully, the exploration of my physical health was a simpler affair. I describe Guillestre as “not particularly special”, but it’s smack bang in the middle of one of the most beautiful regions on Earth. An eMTB rental place opened a few years ago, and during my stay I’d been renting a bike 2-3 times per week. I’d explored the valley by bike plenty of times before, but having an eMTB unlocked routes previously unavailable to me — particularly in my physical state at the time. Almost every time I went out, I’d round a new corner and exclaim “HOLY SHIT” to nobody in particular as a new vista flooded into view. Early in the trip I’d picked one of the peaks and decided that it’d be fun to actually get up there — two weeks later, when I did manage it, it took my breath away so sharply that I had to get off the bike and fight back tears for a moment. If anyone asks, it was the altitude.
The pure joy this brought me gave very clear answers very quickly. Neglecting my health was robbing myself of the joy of exploring the outdoors as well as making my entire life worse. Reversing that course would be a huge step in helping everything else.

Towards the end of one particularly enjoyable ride, I was blasting along a trail when, out of nowhere, the bike was no longer underneath me and trees were whipping by at a terrifying rate. I awoke in a crumped pile at the bottom of a tree halfway down a ravine with my Apple Watch wailing and on the brink of calling the emergency services. I nearly let it. A few minutes of exploratory movements slowly ruled out a broken leg, and I started the agonising clamber back up to the path — made significantly more challenging by finding the bike halfway up. eMTBs are heavy at the best of times, but with a failed front tyre and what feels like a broken leg that’s somehow still working, it was agony. Once at the path, I carried the bike very slowly — and in a lot of pain — off the side of the mountain and called for help.
Luckily, I escaped what should have been broken bones and and airlift to hospital with “only” a hairline-fractured rib and extreme bruising down the side of my torso, hip, and leg. Even the bike survived largely unscathed — a couple of new spokes and it was good to go. Revisiting the crash site revealed what had happened: a moss-covered rock had caught a spoke in the front wheel, ripping the bike out from under me and sending me flying down the ravine, which thankfully was just “extremely steep” rather than “a vertical cliff”. I’d bounced off a large, flat rock before colliding with a cluster of small trees. Had the rock been pointy, things would have been a lot worse. Had the trees not been there, I’d have gone much further down into the ravine, possibly into the river at the bottom. Finally, the data on my bike computer showed that I’d been going much faster than was sensible for the trail, which is something an eMTB is great at doing.
Lessons learned, I hopped back onto a bike as soon as I was physically able — I couldn’t let myself get scared away from something that brings so much joy.
Three weeks after my arrival — and a few days after my crash — I hobbled out of the car and onto the platform of the local train station to greet the sunrise and the overnight train that was carrying my wife.
Over the following days I recounted my three weeks of solitude, sharing the joys of the bike rides and the darkness of the bad days, trying my best to make the jumble of thoughts somewhat coherent. This process started to help them arrange themselves better in my mind, and ever so slowly, a way out started to form.
A couple of days before our return to Sweden, we came down from the mountains for a day trip to Monaco to eat a horrendously fancy lunch and people-watch rich folk (it’s fun — try it some time!). The novelty of an (admittedly delicious) €80 fish lunch while watching impossibly well-dressed socialites abandon their Ferraris in the street, safe in the knowledge a valet would appear out of nowhere to deal with them obviously set my mind free, because on the drive home my wife and I had one of those conversations that end up defining the trajectory of your life.
The road slowly ascended up into the mountains, clinging to the side of a large riverbed. At other times of the year, the banks swell with snowmelt cascading down towards the Mediterranean ocean. Today, a tiny trickle is barely visible. The river, the road, and my car are enveloped by cliffs hundreds of metres high on either side, swallowing the light from the sunset and leaving just greyscale everywhere the car’s headlights can’t reach. As civilisation dwindles, my way out has become clear:
-
I must make an effort to improve and prioritise my physical health. An obvious one to get started.
-
I must let go of my identity as an “indie developer” and the attachment I have to individual pieces of coding work — particularly the idea that “code quality” and “commercial success” have absolutely anything to do with one another. I need to think and act like a small business owner, not a developer, and be at peace that decisions made in that mindset may be at odds with what a developer might want.
-
I must resolve the tension that paid client work brings to my own aspirations of what being a successful small business owner looks like. This means no longer accepting paid client work because I have to — client work must make sense for the company’s expertise and products. If a piece of client work doesn’t suit the company’s strengths or make the company stronger, it shouldn’t be accepted. If I can’t do this within six months, I need to throw in the towel and shut down the company.
Greyscale gives way to complete darkness as the road narrows and gets even twistier. Together, we come to a conclusion that’s as clear as the stars above — in order to move forward, I have to let go of the identity I’ve held for myself for nearly twenty years, and learn to change how I define my own self-worth. To let go of what previously defined whether I’d done a good job or not. To somehow not take it personally when my best programming work doesn’t result in commercial success. On top of all that, I needed to figure out how to allow the company to survive without selling half of its time to external clients within six months.
The Herculean nature of my “way out” probably should have crushed my spirits even more. However, simply finding an answer was such a breakthrough that it felt like half the challenge was already overcome.
The mountain pass had long lost any semblance of civilisation. Street lights were a distant memory, and we’re crawling up hairpins at 20 km/h — my little car slowly scaling the mountain. I feel free. The way forward is going to be tough, but at the very worst it’ll be over in six months.
Summer 2022 — 18 Months Later
“Alright, I think it’s time to make a decision.”
My wife and I are trying to find answers that weren’t there in note-covered cards strewn across our dining room table. A laptop displays market research and mock advertising as I tap through a prototype app I’d hacked together over the course of a couple of weeks.
“At some point, we need to abandon this idea or jump in with both feet and go for it. The core question is: Is this idea good enough to invest a lot of time and,” — I switch over to a spreadsheet labelled Estimated MVP Costs — “a lot of money in to see if it’ll actually work?”
In the eighteen months or so since returning from that trip to France, things have been, slowly but surely, recovering. The most meaningful event was a successful partnership with a camera manufacturer to integrate them with the Cascable app. This, on top of the financial contribution, helped me successfully switch my mindset — for the most part — away from “developer” to “business owner”, and I’m able to take a more pragmatic approach to my decision making. Alongside the camera manufacturer integration, we did a very large overhaul of an ageing component of the app. Much like the disastrous Cascable 4.0 update in 2019, this was a modernisation of an existing feature-set. Unlike 2019, there was no pressure for it to increase revenue — it was done because it needed doing, and that was all. Business Owner Daniel decided it was time to revamp the app’s App Store presence, so a decent investment was put into making sorely-needed new screenshots, video, and marketing copy.
Since then, sales have risen and combined with more B2B revenue from CascableCore, the company is able to focus 100% of its time to Cascable projects. It’s hard to pinpoint exactly what caused app sales to rise — perhaps this time the revamp of an existing feature was meaningful to revenue. Perhaps the better App Store presence has boosted things. Perhaps my attitude shift and the confidence boost from landing the camera manufacturer deal has let me move forward in a better way. Most likely, it’s a little of each.
I’m not perfect, of course. I continue to repeatedly declare that I’m going to dedicate more time to making marketing content, and I repeatedly fail to do so. I’m trying, though! Old habits die hard. The tendrils of failure continue to pop up now and then and assert their grip — every time I see another indie post success or brag about sales, they slither into my soul for a moment — but by now I can largely brush them away, and they’re controlled enough that I can identify them as a personality trait that can likely be soothed with counselling.
The freedom gained from letting go of the “this single app must earn all of the revenue and if it doesn’t I’m a failure” mindset has allowed me to poke at an idea for a new app that’s been rattling around in my head for years. Indie Developer Daniel would have just jumped right in and started writing code, but Business Owner Daniel is here now. We did market research with user surveys and questionnaires, feeling out the market a little. We put together sample marketing, figuring out who this might be marketed towards and what features would be important to them. We had screenshots and adverts before a single line of code was written — and then I wrote a small prototype to make sure the idea would, you know, actually work technically. Nearly twenty years at this, and I’ve never done it this way ‘round before — usually it’s code first, find the market later. If that’s not a great example of “success can hide a lot of failures”, I don’t know what is.
“The core question is: Is this idea good enough to invest a lot of time and,” — I switch over to a spreadsheet labelled Estimated MVP Costs — “a lot of money in to see if it’ll actually work?”
A moment of nervous silence.
“Yes. I think it is.”
More silence.
“Me too.”
Epilogue & Loose Ends
Physical Health
A few weeks after returning from France, I drummed up the courage to go into a gym and ask about a personal trainer with the goal of getting into a routine to turn my momentum around and slowly start improving my health. By sheer happenstance, I got paired with a trainer whose attitude towards the craft inspired me so much that my intended few weeks just kept on going — I’m continuing training to this day. Thanks to her, I did a mountain bike race last year, and am working towards doing it again this year with an even better time. This is far beyond any goal I’d originally set, and I still can’t quite believe it myself.

I was trying to pull off a “determined” look, but ended up with “bemused”.
Excellent Humans
Thanks to my tendency to turn in on myself during times of pain, a number of people were immeasurably helpful to me without actually realising the magnitude of what I was going through. I have a tradition of reaching out to people who have had an especially meaningful impact on my life at the end of each year so they’ve all largely been thanked in person, but still:
-
Thank you to the folk who helped me with negotiating the camera manufacturer partnership in 2020/21 — your business acumen saved my bacon.
-
Thank you to Claude for fishing me out of a ravine with a broken ego and a broken bike.
-
Thank you to my personal trainer who guided me through a world full of people very much Not Like Me to get me on the right health path (and then somehow to a race).
-
Thank you to various friends and strangers who, with no knowledge of my situation, performed perfectly innocuous kind gestures that happened to be incredibly meaningful.
-
And of course, thank you to my wife who — even at the best of times will put up with my shit — stood by me as a I broke down, had the strength to let me leave for three weeks of solitude thousands of kilometres away, then helped me put myself back together again. Words, gifts, acts, nor cold hard cash could ever communicate my gratitude.
Final Word
If you made it this far, thank you! As I mentioned at the beginning, publishing this (kind of against my better judgement still) is aimed to draw a line under these past few years so I can leave the sorrow behind and take the lessons forward.
At the time of writing (well, typing it up), I’m fully focused on the new app idea mentioned above, and the aim is to launch a limited beta test of it around the end of January or so. I’m excited! If you’d like to follow along, you can do so by following me on Mastodon. I also plan to post some of the more interesting technical things on this blog — back to business as usual, finally.